包含多个段的程序
第六章内容比较少,基本都是实操,通过实验可以明白如何写、为什么要写多个段的汇编程序,以及段的一些特征。
检测点6.1.1
assume cs:codesg
codesg segment
dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h
start: mov ax,0
mov ds,ax
mov bx,0
mov cx,8
s: mov ax,[bx]
mov cs:[bx],ax
add bx,2
loop s
mov ax,4c00h
int 21h
codesg ends
end start检测点6.1.2
assume cs:codesg
codesg segment
dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h
dw 0,0,0,0,0,0,0,0,0,0
start: mov ax,cs
mov ss,ax
mov sp,24h ;SS:SP指向0:24H
mov ax,0
mov ds,ax ;DS指向0
mov bx,0 ;[BX]初始化
mov cx,8 ;循环8次
s: push [bx] ;入栈
pop cs:[bx] ;出栈
add bx,2
loop s
mov ax,4c00h
int 21h
codesg ends
end start实验5.1
assume cs:code,ds:data,ss:stack
data segment
dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h
data ends
stack segment
dw 0,0,0,0,0,0,0,0
stack ends
code segment
start: mov ax,stack
mov ss,ax
mov sp,16
mov ax,data
mov ds,ax
push ds:[0]
push ds;[2]
pop ds:[2]
pop ds:[0]
mov ax,4c00h
int 21
code ends
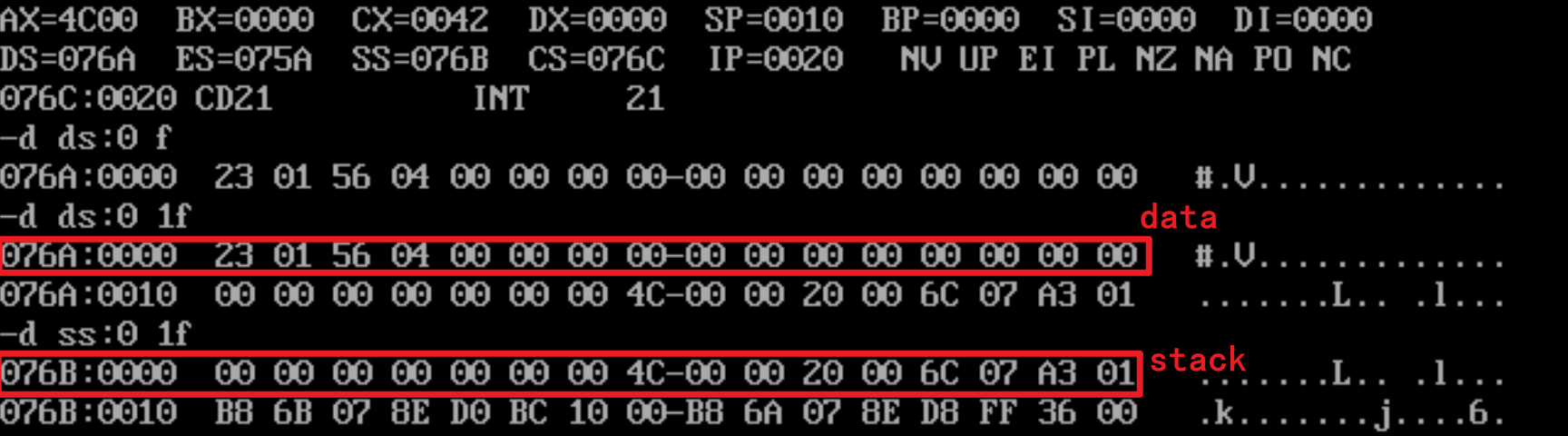
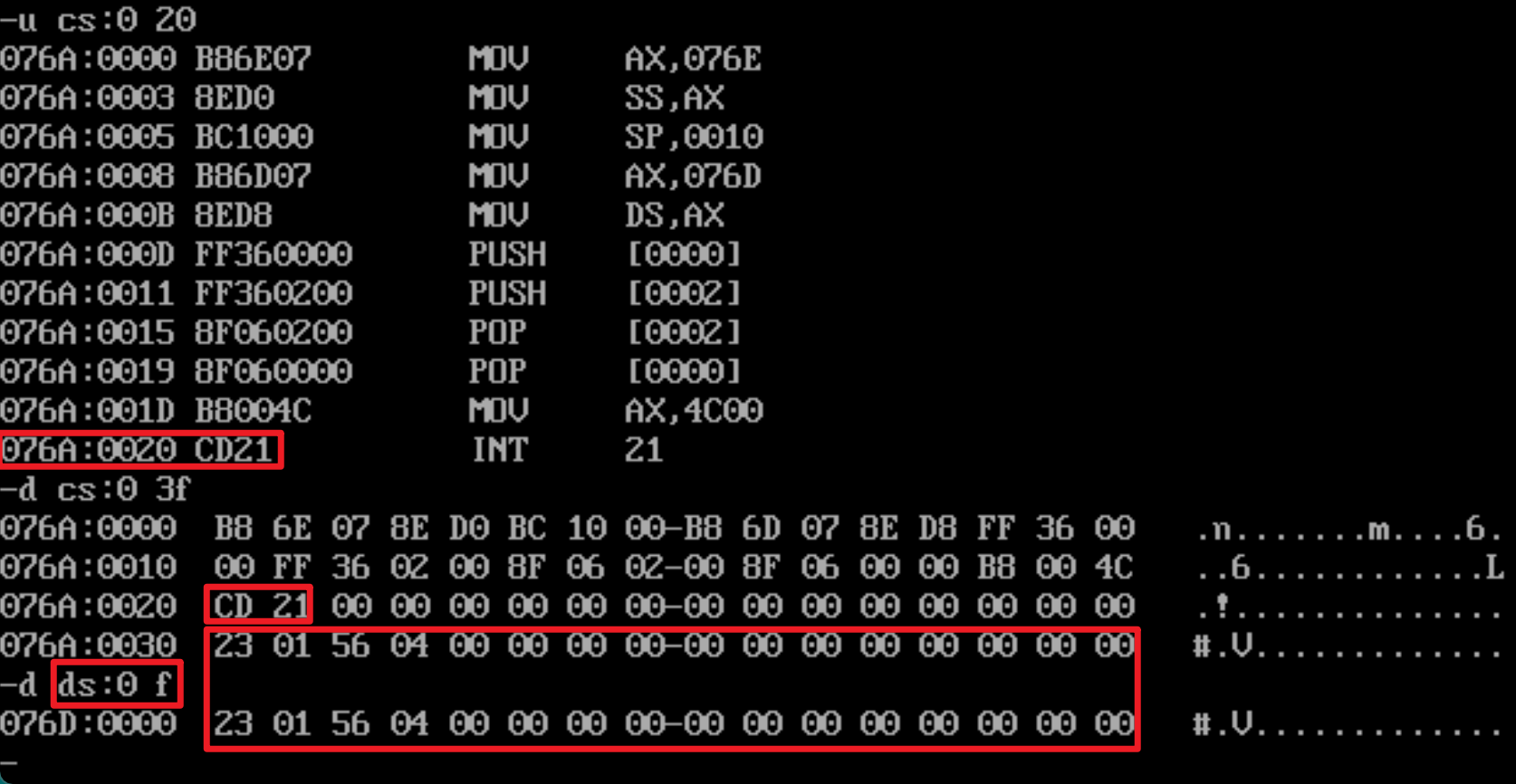
end start需要先执行好初始化数据段和栈段的语句
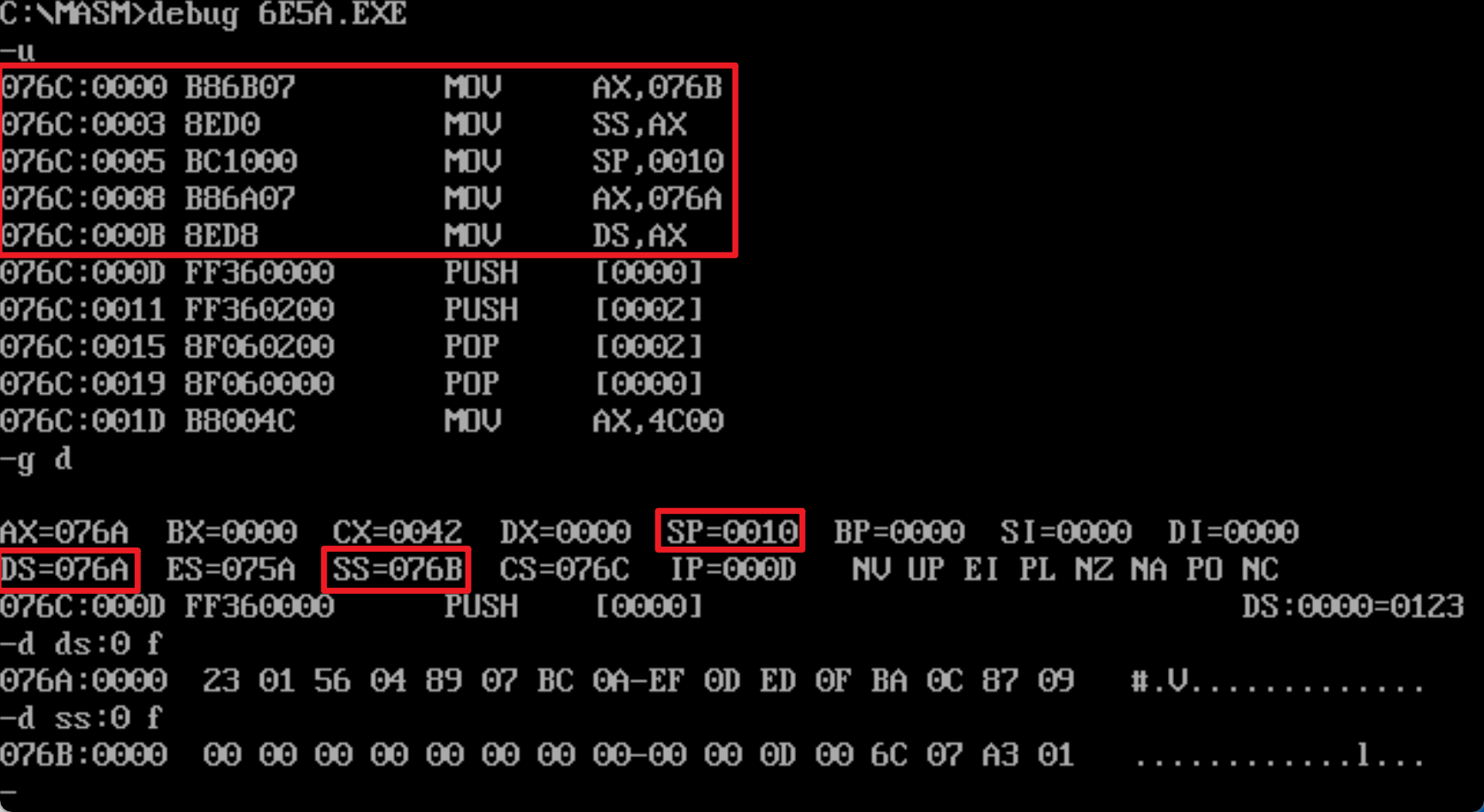
程序返回前,CS、SS、DS段地址均不变,data段数据出入栈后又恢复为初始状态了
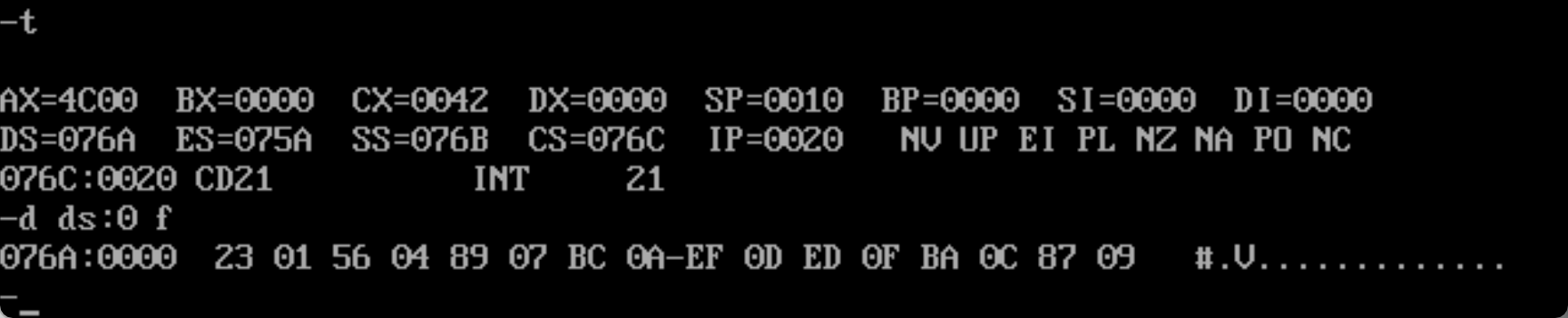
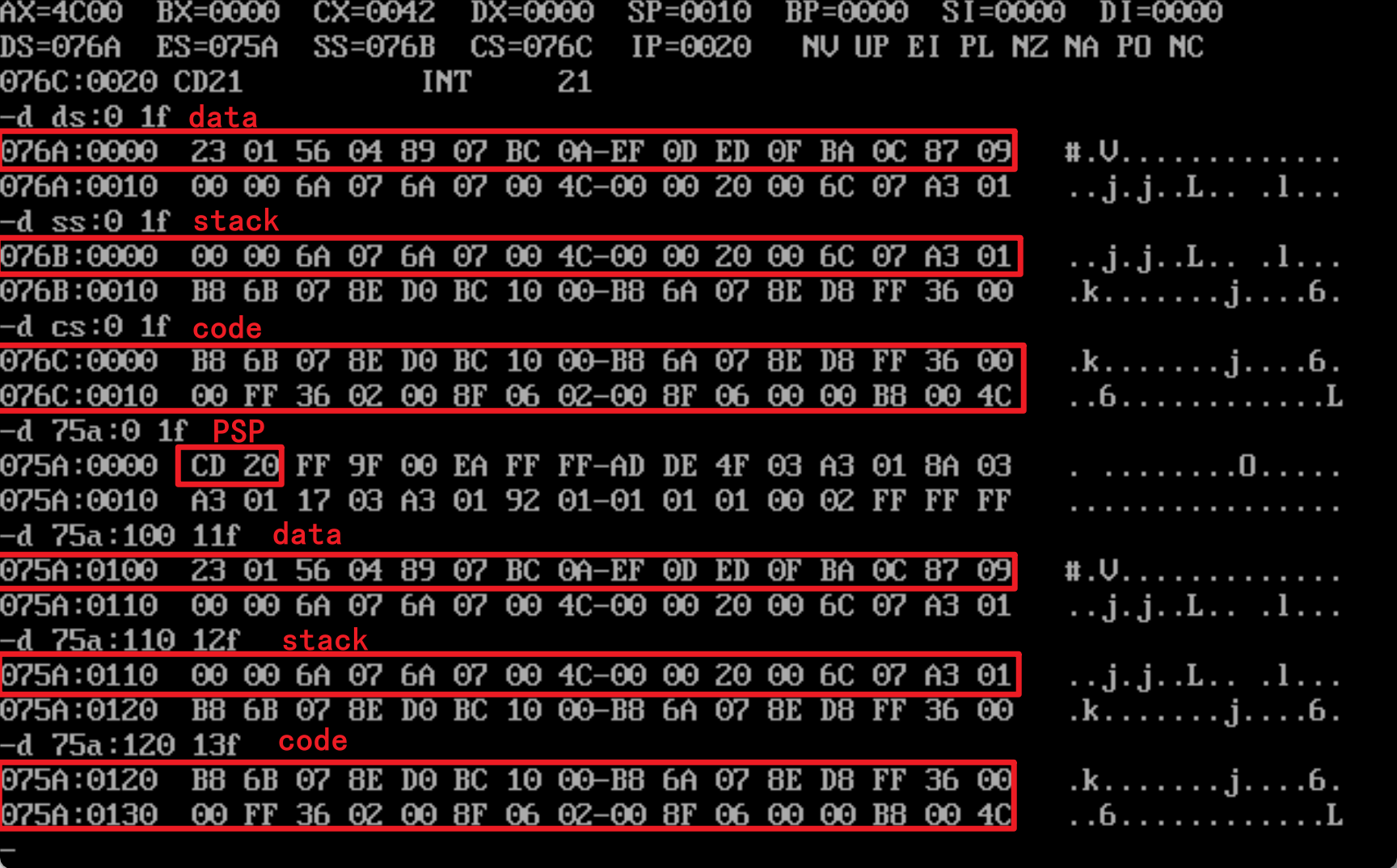
程序加载后:初始的DS值为75A,也就是PSP从75A:0开始
初始化data和stack段后:
DS的值为76A,也就是data的段地址为76A;
SS的值为76B,也就是stack的段地址为76B;
CS的值为76C,也就是code的段地址为76C;
设code段地址为X(76C),data的段地址为X-2(76A),stack的段地址为X-1(76B)
| 地址 | 类型 |
|---|---|
| 75A:0 | PSP |
| 75A:100 | data |
| 75A:110 | stack |
| 75A:120 | code |
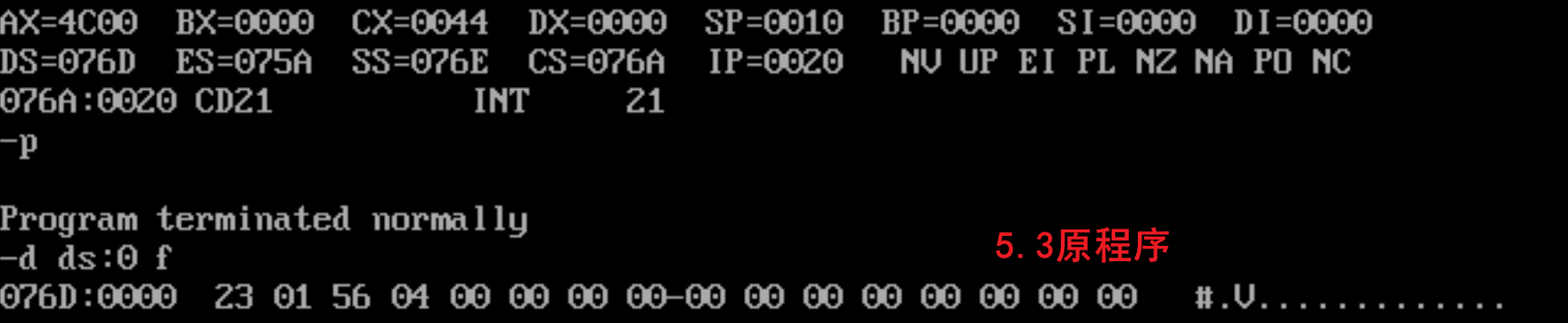
实验5.2
assume cs:code,ds:data,ss:stack
data segment
dw 0123h,0456h
data ends
stack segment
dw 0,0
stack ends
code segment
start: mov ax,stack
mov ss,ax
mov sp,16
mov ax,data
mov ds,ax
push ds:[0]
push ds:[2]
pop ds:[2]
pop ds:[0]
mov ax,4c00h
int 21h
code ends
end start程序返回前,data段中的数据为:
在源程序中,用dw定义的数据是:0123H,0456H,而data段数据的末尾(就是0456H的后面)并没有像上一个实验一样,data段紧接着就是stack段,而是在data段后面都是0,在76A:0010(76B:0)才开始是stack的数据,说明了一个段至少有16个内存单元(也就是至少是一个段地址:0-10H)
即如果段总的数据占N个字节,程序加载后,实际占有的空间为(N/16(取整数位)+1)x16
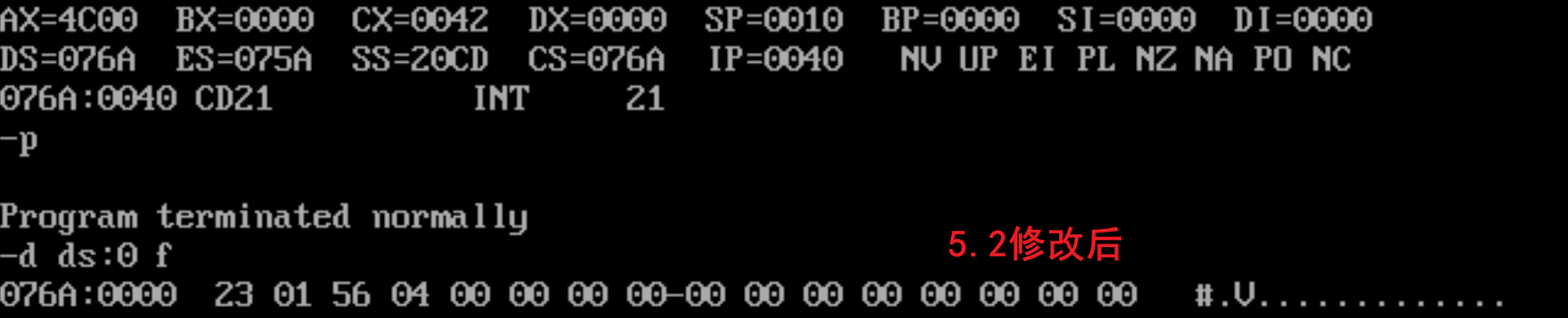
实验5.3
assume cs:code,ds:data,ss:stack
code segment
start: mov ax,stack
mov ss,ax
mov sp,16
mov ax,data
mov ds,ax
push ds:[0]
push ds:[2]
pop ds:[2]
pop ds:[0]
mov ax,4c00h
int 21h
code ends
data segment
dw 0123h,0456h
data ends
stack segment
dw 0,0
stack ends
end start程序返回前data段数据与CS、SS、DS的值:

设这个程序中code段的段地址为X(76A),data段的段地址为X+3(76D)(code段长),stack段的段地址为X+4(76E)
可以看到,在code段后末尾的下一行就是data段了
这个源程序代码的顺序是code段-data段-stack段,此处也体现了这个顺序
实验5.4
如果将实验5的1-3的最后一条伪指令end start改为end(不指明程序入口),我推测只有5.3的程序可以正确执行,因为5.3的程序开头就是code段,所以程序加载进内存,CS就能直接指向实际的汇编指令,而不是像5.1和5.2一样,因为data、stack写在code前面,如果没有指明程序入口,CS就会先指向data、stack。(此处可见书中6.1)
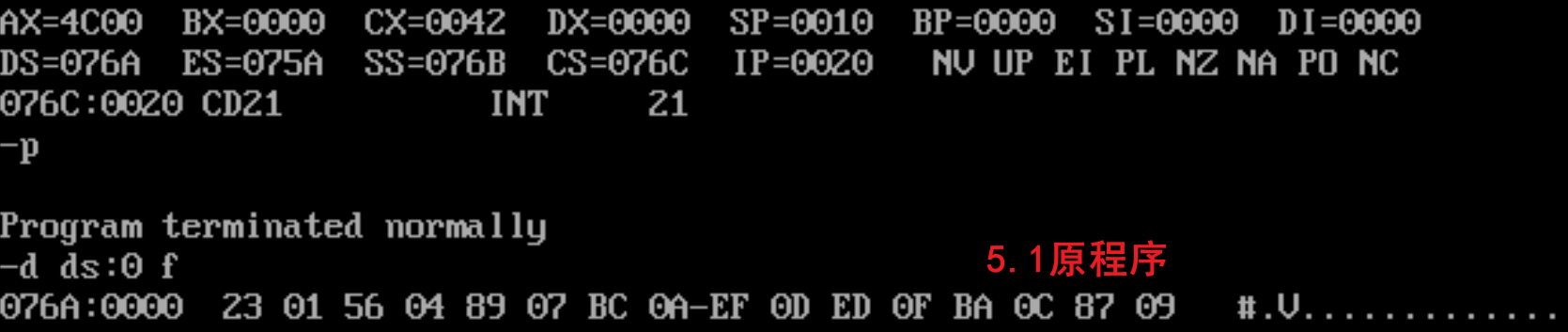
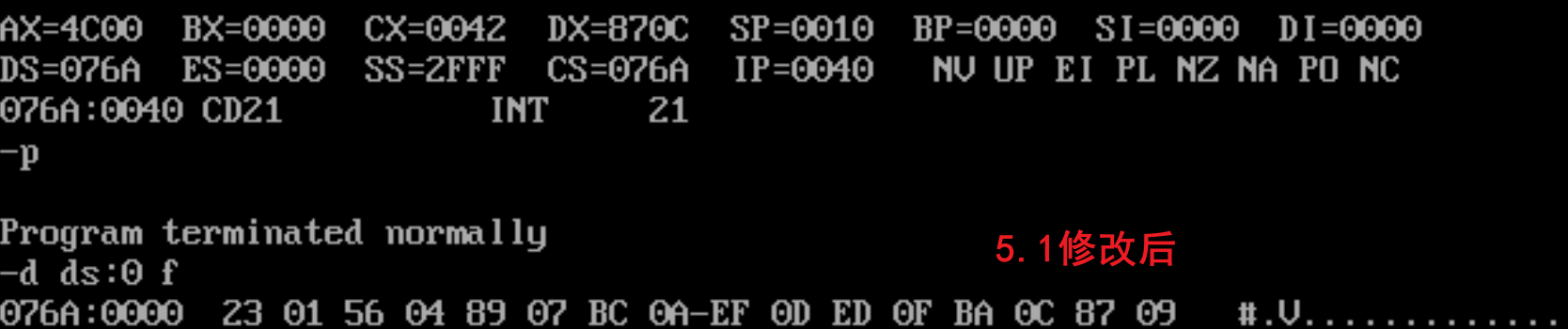
实际测试:
- 5.1:
- 5.2:

- 5.3:

实际执行结果是所有程序都能正常运行(不管是command直接跑还是debug调试),并且最终data段的数据和修改前的程序都一样。但只需要在debug加载程序后,按r就可以看到将要执行的是data中的数据所翻译的机器码,逻辑上确实是错误的,但可能是data、stack的数据所代表的机器码,实际对这两个程序没有什么影响,所以最终结果没问题。
实验5.5
需要操作三个数据段,除了DS和ES,没有其他段寄存器用了,也没法把c段作为栈(db是字节型,栈的最小操作单位是字型)。
还是不太熟练,写了两遍,然后得到了比较正常的方法
1.DS指向a,ES指向b,SS指向c,也就是把栈寄存器直接当DS和ES一样用,测试没问题,但肯定不符合规范
2.将DS指向a,ES指向b,先把a和b相加,相加结果存储到b;然后将DS指向c,把b的内容搬到c。但这样就把b原有的数据覆盖了
2已经差不多了,稍作改动就没什么问题了:
将DS指向a,ES指向c,先把a搬到c
将DS指向b,把b送入dl寄存器,然后将bl和c依次相加
assume cs:code
a segment
db 1,2,3,4,5,6,7,8
a ends
b segment
db 1,2,3,4,5,6,7,8
b ends
c segment
db 0,0,0,0,0,0,0,0
c ends
code segment
start: mov ax,a
mov ds,ax
mov ax,c
mov es,ax
mov bx,0
mov dl,0
mov cx,8
s1: mov dl,ds:[bx]
mov es:[bx],dl
inc bx
loop s1
mov ax,b
mov ds,ax
mov dl,0
mov bx,0
mov cx,8
s2: mov dl,ds:[bx]
add es:[bx],dl
inc bx
loop s2
mov ax,4c00h
int 21h
code ends
end start实验5.6
assume cs:code
a segment
dw 1,2,3,4,5,6,7,8,9,0ah,0bh,0ch,0dh,0eh,0fh,0ffh
a ends
b segment
dw 0,0,0,0,0,0,0,0
b ends
code segment
start: mov ax,b
mov ss,ax
mov sp,16
mov ax,a
mov ds,ax
mov bx,0
mov cx,8
s: push ds:[bx]
add bx,2
loop s
mov ax,4c00h
int 21h
code ends
end start更灵活的定位内存地址的方法
and 和 or 指令
按位与、按位或
| 符号 | 描述 | 运算规则 |
|---|---|---|
| &、AND | 与 | 两个位都为1时,结果才为1 |
| |、OR | 或 | 两个位都为0时,结果才为0 |
字母大小写转换
| 字母 | 十六进制 | 二进制 | 十进制 |
|---|---|---|---|
| A | 41H | 0100 0001 | 65 |
| a | 61H | 0110 0001 | 97 |
同一个字母,大小写的区别就是二进制第6位,大写是0,小写是1(十六进制相差20H,十进制相差32)
add al,11011111b ;小写转大写
or al,00100000b ;大写转小写寻址方式
| 形式 | 名称 | 表示地址的特点 | 意义 | 示例 |
|---|---|---|---|---|
| [idata] | 直接寻址 | 1个常量(立即数) | 直接定位一个内存单元 | mov ax,ds:[200] |
| [bx] | 寄存器间接寻址 | 1个变量 | 间接定位一个内存单元 | mov bx,0 mov ax,[bx] |
| [bx+idata] idata[bx] |
寄存器相对寻址 | 1个变量+1个常量 | 一个起始地址的基础上用变量间接定位一个内存单元 | mov bx,4 mov ax,[bx+200] |
| [bx+si] [bx] [si] |
基址变址寻址 | 2个变量 | mov ax,[bx+si] | |
| [bx+si+idata] idata [bx] [si] [bx].idata [si] [bx] [si].idata |
相对基址变址寻址 | 2个变量+1个常量 | mov ax,[bx+si+200] |
[bx].idata[si]之类的形式,[bx]、[si]和.idata之间的空格可有可无
问题9.7
将4行字符串的前三个字母(即对应从0开始的列的3-6列)转为大写
需要使用4x4次的二重循环
assume cs:codesg,ss:stacksg,ds:datasg
stacksg segment
dw 0,0,0,0,0,0,0,0
stacksg ends
datasg segment
db '1. display '
db '2. brows '
db '3. replace '
db '4. modify '
datasg ends
codesg segment
start:mov ax,stacksg
mov ss,ax
mov sp,16
mov ax,datasg
mov ds,ax
mov bx,0 ;定位每行起始地址的变量
mov cx,4
s0:mov si,0 ;新的一行,重置要修改的列偏移量为0
push cx ;将外层循环的cx压入栈中
mov cx,4
s:mov al,ds:[bx+3+si]
and al,11011111b
mov ds:[bx+3+si],al ;转大写
inc si ;下一个要修改的列相对于起始列的地址
loop s
add bx,16 ;下一行
pop cx ;恢复外层循环的cx
loop s0
mov ax,4c00h
int 21h
codesg ends
end start数据处理的两个基本问题
bx、si、di和bp
8086CPU只有这4个寄存器可以用于[…]中的寻址
[bp]的默认段寄存器为ss,bp和bx类似,但bp不能拆分为两个8位寄存器
mov ax,[bx] ;默认段寄存器为ds
mov ax,[bp] ;默认段寄存器为ss在哪里?有多长?
机器指令处理的数据在:CPU内部(CPU指令缓冲器中存储了机器指令中的数据,即立即数;寄存器)、内存、端口
不同情况下,指明指令处理的数据有多长有不同的方法:
寄存器
mov ax,1 mov bx,ds:[0] ;ax、bx是16位寄存器,进行字操作 mov al,2 inc al ;al是8位寄存器,进行字节操作操作符 X ptr(在没有寄存器参与的情况下)
mov word ptr [0],1 ;word ptr指明指令访问的内存单元是一个字单元 mov byte ptr [bx] ;字节,以此类推其他方法
有些指令默认了访问的是字还是字节,如push [1000],push、pop默认也只能进行字操作
div(除法)、dd(双字)和dup
- div指令分为两种情况:
| 被除数 | AX(16位) | (DX*10000H)+AX(32位) |
|---|---|---|
| 除数 | reg/内存(8位) | reg/内存(16位) |
| 商 | AL | AX |
| 余数 | AH | DX |
div byte ptr ds:[0] ;8位内存
;(ax) / (ds*10h+0) = (al) ······ (ah)
div ax ;16位reg
;(dx*10h+ax) / ax = (ax) ······ (dx)dd用于定义dword(double word),长32位
dup
db 3 dup (0) ;此处的3是十进制,3字节填满0 db 3 dup (0,1,2) db 3 dup ('abc','ABC')
实验7
折腾了好久。
assume cs:codesg
data segment
db '1975','1976','1977','1978','1979','1980','1981','1982','1983'
db '1984','1985','1986','1987','1988','1989','1990','1991','1992'
db '1993','1994','1995'
;以上是表示21年的21个字符串
dd 16,22,382,1356,2390,8000,16000,24486,50065,97479,140417,197514
dd 345980,590827,803530,1183000,1843000,2759000,3753000,4649000,5937000
;以上是表示21年公司总收入的21个dword型数据
dw 3,7,9,13,28,38,130,220,476,778,1001,1442,2258,2793,4037,5635,8226
dw 11542,14430,15257,17800
;以上是表示21年公司雇员人数的21个word型数据
data ends
table segment
db 21 dup ('year summ ne ?? ')
table ends
codesg segment
start: mov ax,data
mov ds,ax
mov si,0
mov di,0
mov ax,table
mov es,ax
mov bx,0
mov cx,21
s: mov bp,0 ;数组year位于开头
mov ax,ds:[bp+si]
mov es:[bx],ax
mov ax,ds:[bp+si+2]
mov es:[bx+2],ax ;year
mov bp,84 ;数组summ与开头间隔84
mov ax,ds:[bp+si]
mov es:[bx+5],ax
mov ax,ds:[bp+si+2]
mov es:[bx+7],ax ;summ
mov bp,168 ;数组ne与开头间隔168
mov ax,ds:[bp+di]
mov es:[bx+10],ax ;ne
mov ax,es:[bx+5] ;收入低16位
mov dx,es:[bx+7] ;收入高16位
div word ptr es:[bx+10] ;人均收入 = 收入 / 人数
mov es:[bx+13],ax
add si,4 ;dword类型定位到下一个元素
add di,2 ;word类型定位到下一个元素
add bx,10h ;table定位到下一行
loop s
mov ax,4c00h
int 21h
codesg ends
end start转移指令的原理
可以修改IP或CS和IP的指令都称为转移指令
8086CPU的转移行为:
- 段内转移(修改IP)
- 短转移 jmp short(-128 ~ 127)8位
- 近转移 jmp near(-32768 ~ 32767)16位
- 段间转移(修改CS和IP)
转移指令分为:
- 无条件转移(jmp)
- 条件转移(jcxz)
- 循环指令(loop)
- 过程
- 中断
offset
codesg segment
start: mov ax,offset start ;ax=0
s: mov ax,offset s ;ax=3(上一条指令的长度是3字节)
codesg ends
end startjmp
jmp short s ;短转移。(IP) = (IP)+8位位移
jmp near ptr s ;近转移。(IP) = (IP)+16位位移
;位移=标号处的地址 - jmp指令后的第一个字节的地址
;短转移和近转移只修改IP,对应的机器码只包含位移,不包含实际要转移到的IP
jmp far ptr s ;段间转移(远转移),机器码内包含段地址和偏移地址
jmp 16位reg ;将IP修改为16位reg里的内容
jmp word ptr ds:[0] ;段内转移。IP修改为对应内存地址处的一个字
jmp dword ptr ds:[0] ;段间转移,IP修改为对应内存地址处低位的字,CS修改为高位的字jcxz和loop
jcxz是有条件转移指令,所有有条件转移指令都是短转移(8位),对应机器码中包含位移
jcxz 标号 ;如果cx=0,转移到标号处(IP=IP+8位位移)loop是循环指令,所有循环指令都是短转移
loop 标号 ;cx=cx-1,如果cx不等于0,转移到标号处(IP=IP+8位位移)
;如果cx=0,程序继续向下执行根据位移转移的意义与位移超界
位移方便了程序段在内存中的浮动装配;反之,如果包含了标号的具体地址,就会严格限制了程序段的偏移地址,导致出错
位移超界时编译器将报错
jmp 段地址:偏移地址只能在debug中使用,不能在源程序中使用
实验8
没运行前推测是不能正确返回的,实际运行起来是正常的,想了下是自己没有理解好位移转移,把jmp位移当成了指定地址
错误的推测:

debug查看内存: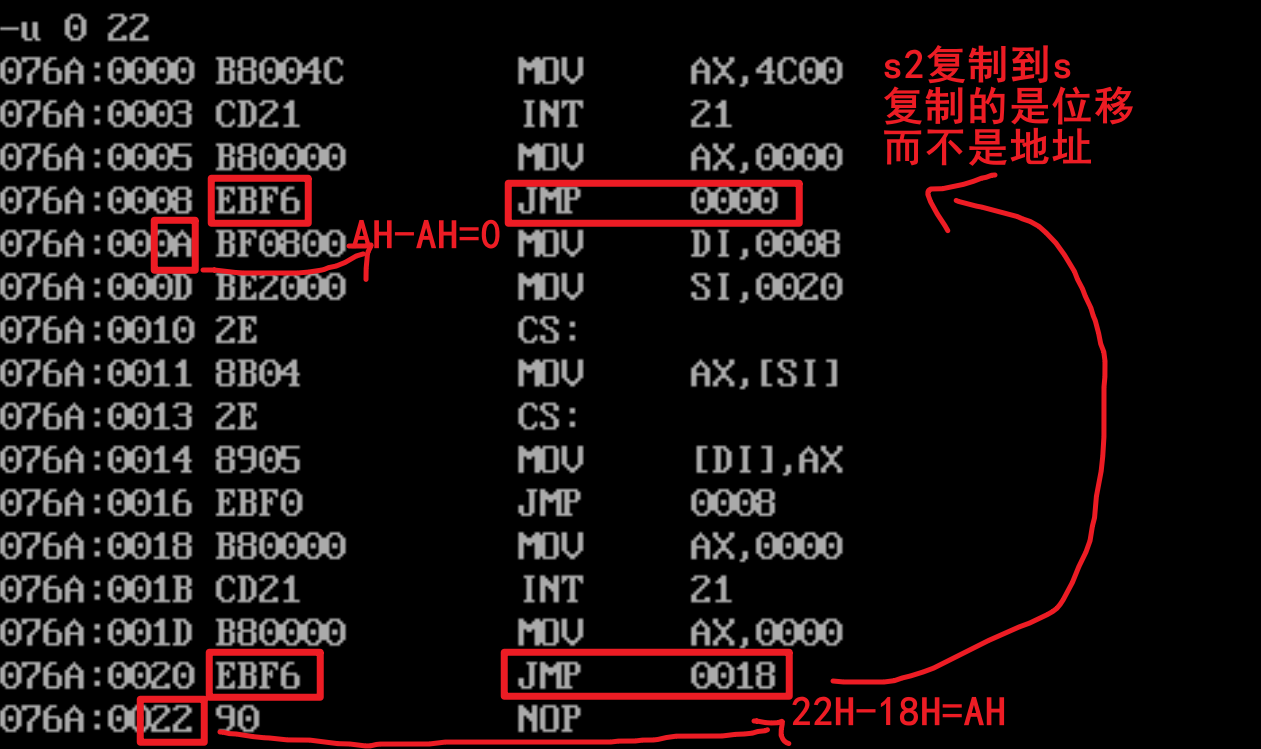
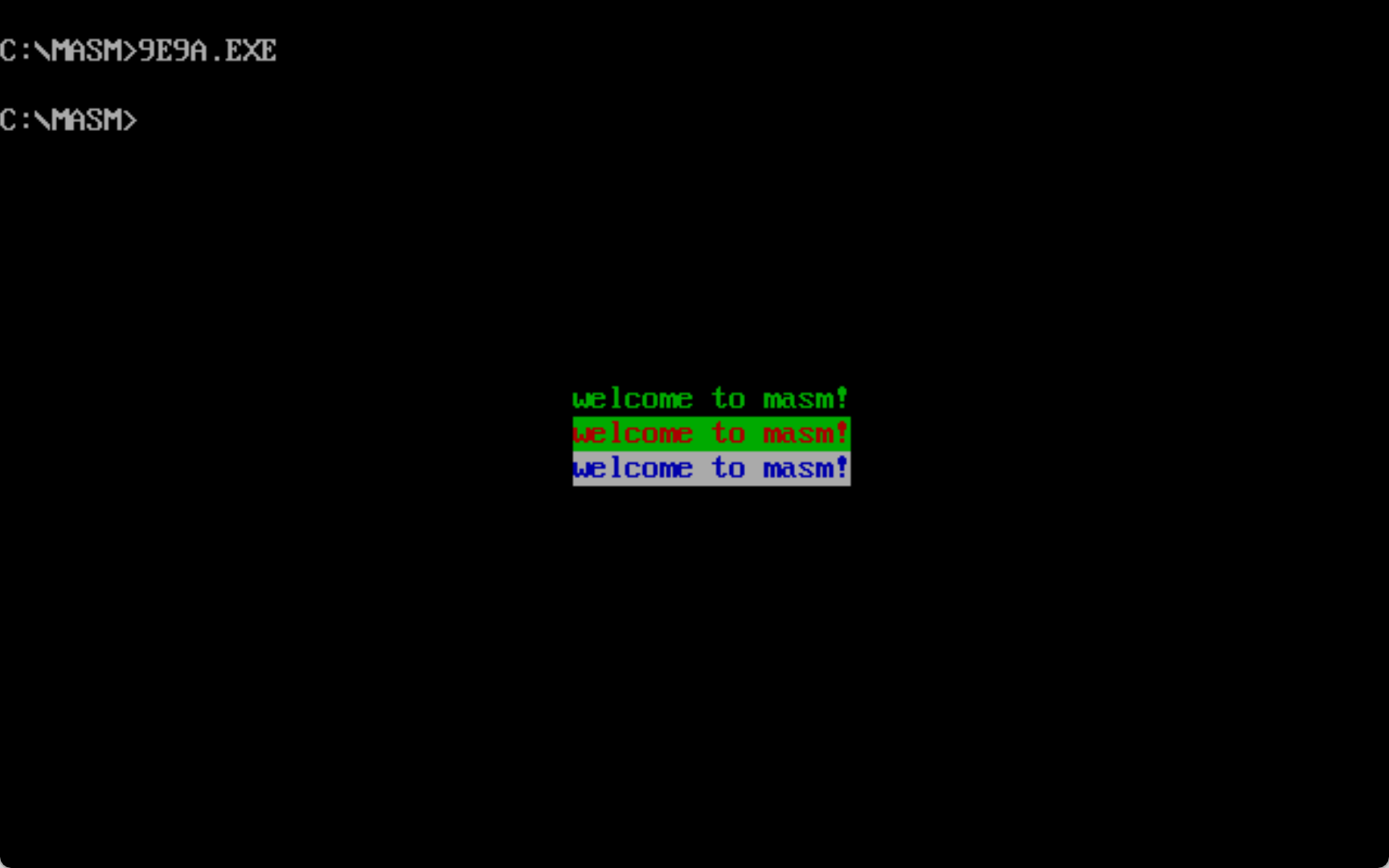
实验9
assume cs:codesg
datasg segment
db 'welcome to masm!'
db 10b,100100b,1110001b ;颜色信息
datasg ends
stacksg segment
dw 8 dup(0)
stacksg ends
codesg segment
start: mov ax,0b800h
mov ds,ax ;ds指向显示缓冲区
mov ax,datasg
mov es,ax
mov bp,06e0h ;12行
mov di,0
mov cx,3
s0: push cx
mov ah,es:[10h+di]
mov bx,0 ;datasg
mov si,66 ;33列
mov cx,16
s: mov al,es:[bx]
mov ds:[bp+si],ax
add si,2
inc bx
loop s
pop cx
add bp,0a0h ;下一行
add di,1 ;读取下一行的颜色
loop s0
mov ax,4c00h
int 21h
codesg ends
end start学了将近一周,终于能输出文字了